Fast Instance Failover for Tightly-Coupled Jobs
In a previous blogpost I showed a method of doing all-or-nothing scaling using AWS ParallelCluster. This is a great way to save on costs by making sure your job either runs or doesn’t, but what happens when your job can’t execute due to capacity?
In this blog I present a method for re-trying the job quickly on other similar instance types, allowing you to diversify capacity while maintaining the same number of cores-per-instance.
For example, let’s say I have a tightly coupled MPI job that needs 50x c6i.32xlarge instances to run. I enable all-or-nothing scaling to make sure I don’t get partial scaling. I then submit the job and I get the following message:
An error occurred (InsufficientInstanceCapacity) when calling the RunInstances operation (reached max retries: 1): We currently do not have sufficient c6i.32xlarge capacity in the Availability Zone you requested (us-east-2a). Our system will be working on provisioning additional capacity. You can currently get c6i.32xlarge capacity by not specifying an Availability Zone in your request or choosing us-east-2b, us-east-2c.
I know that the c6i.32xlarge, m6i.32xlarge, and r6i.32xlarge all share the same CPU and only differ on the amount of memory:
| Instance Type | Processor | vCPUs | Memory (GB) | On-Demand Cost |
|---|---|---|---|---|
| c6i.32xlarge | 3rd Generation Intel Xeon (Ice lake) | 128 | 256 | $5.44 |
| m6i.32xlarge | 3rd Generation Intel Xeon (Ice lake) | 128 | 512 | $6.144 |
| r6i.32xlarge | 3rd Generation Intel Xeon (Ice lake) | 128 | 1024 | $8.064 |
With this knowledge and the new Fast Instance Failover feature released in AWS ParallelCluster 3.2.0, I can re-try on the m6i and r6i in quick succession until I get the 50 instances my job requires.
I order the instances in the queue from least to greatest cost to ensure I get the cheapest instance type that meets my capacity requirements. This isn’t just limited to 6th generation Intel instances, you can do do this with any set of instances that have the same dimension i.e. vCPU count.
Setup
I configure my queue to have three compute resources (CR’s), c6i.32xlarge, m6i.32xlarge, and r6i.32xlarge in that order:
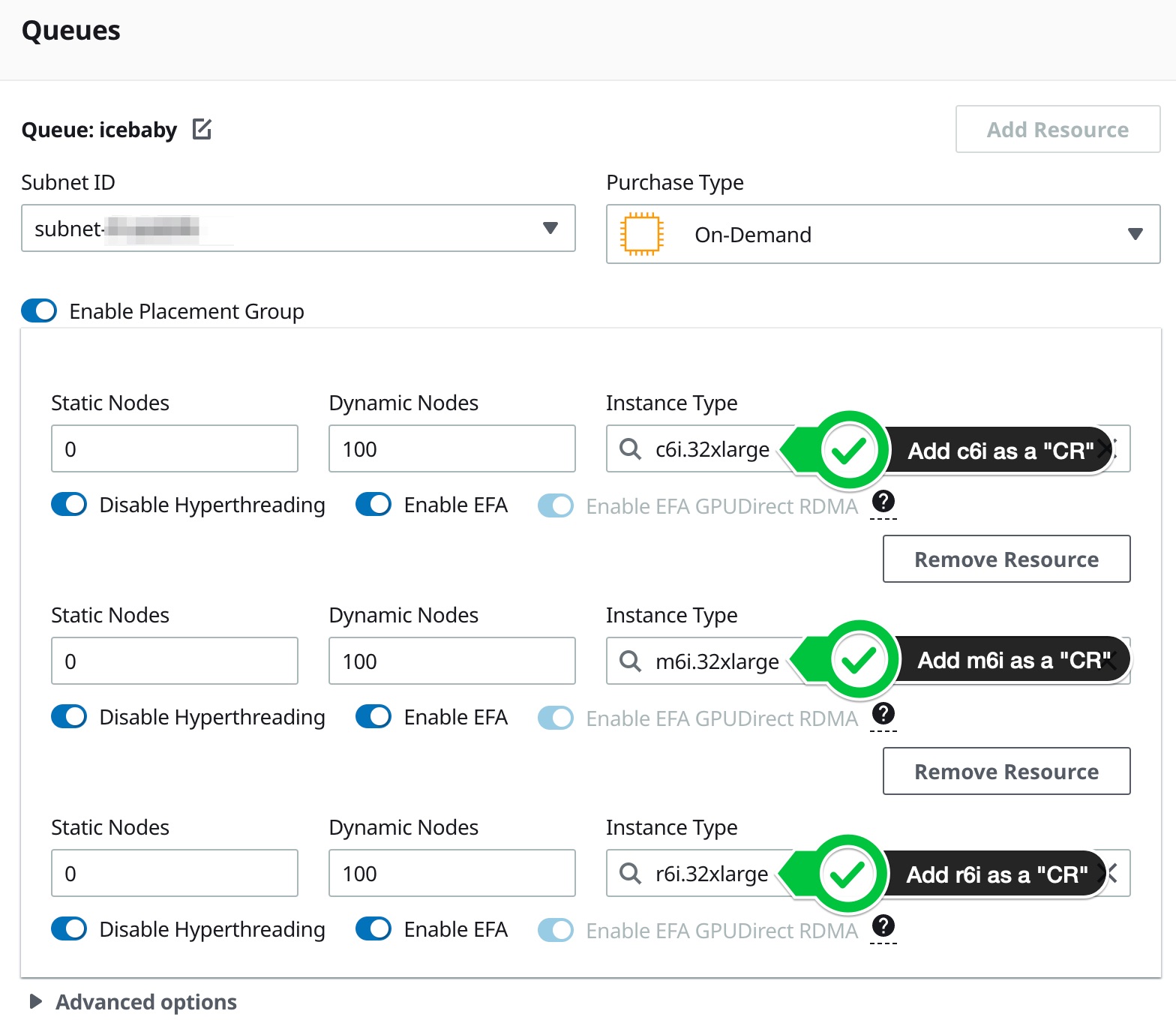
Review the config and make sure they’re all in the same SlurmQueue:
HeadNode:
InstanceType: c6i.xlarge
Ssh:
KeyName: keypair
Networking:
SubnetId: subnet-123456789
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
Dcv:
Enabled: true
Scheduling:
Scheduler: slurm
SlurmQueues:
- Name: icebaby
ComputeResources:
- Name: icebaby-c6i32xlarge
MinCount: 0
MaxCount: 100
InstanceType: c6i.32xlarge
Efa:
Enabled: true
DisableSimultaneousMultithreading: true
- Name: icebaby-m6i32xlarge
InstanceType: m6i.32xlarge
MinCount: 0
MaxCount: 100
Efa:
Enabled: true
DisableSimultaneousMultithreading: true
- Name: icebaby-r6i32xlarge
InstanceType: r6i.32xlarge
MinCount: 0
MaxCount: 100
Efa:
Enabled: true
DisableSimultaneousMultithreading: true
Networking:
SubnetIds:
- subnet-123456789
PlacementGroup:
Enabled: true
Region: us-east-2
Image:
Os: alinux2
Test
Once the cluster is running I can run sinfo and see the instance types:
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
icebaby* up infinite 300 idle~ icebaby-dy-icebaby-c6i32xlarge-[1-100],icebaby-dy-icebaby-m6i32xlarge-[1-100],icebaby-dy-icebaby-r6i32xlarge-[1-100]
Then I can submit a job like:
sbatch --wrap "sleep 60" -N 50 --requeue
Since I have all-or-nothing scaling setup my job gets rejected from the first set of instances:
watch queue
I’ll see my job go into CF state, with c6i instances allocated. This then fails within ~ 30 second and we’ll briefly see it go into PD state, then retry on m6i:
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
2 icebaby interact ec2-user CF 0:16 50 icebaby-dy-icebaby-c6i32xlarge-[1-50]
...
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
2 icebaby wrap ec2-user PD 0:00 50 (BeginTime)
...
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
2 icebaby wrap ec2-user CF 0:14 50 icebaby-dy-icebaby-m6i32xlarge-[1-50]
...
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
2 icebaby wrap ec2-user R 0:05 50 icebaby-dy-icebaby-m6i32xlarge-[1-50]
Conclusion
Workloads with high-cpu requirements that are tightly coupled in-nature, can take advantage of this approach in order to get enough capacity at the cheapest price while maintaining the same number of cores-per-instance.
This approach can be used in other scenarios as well, such as when using Spot Instances, I can specify multiple instance types in order to reduce the chance of getting a Spot interruption or when using GPU instances with very limited capacity due global chip shortages.