Save StarCCM+ State in AWS ParallelCluster 🛟
Spot termination gives a 2-minute warning before terminating the instance. This time period allows you to gracefully save data in order to resume later.
In the following I describe how this can be done with StarCCM+ in AWS ParallelCluster 3.X however this can be generalized to any application that has the ability ot checkpoint and save current state. An example of this is Gromacs, for which I wrote a blogpost on how to enable checkpointing.
Setup
In order for this to work, we’re going to create a script that runs on the Compute Nodes that checks every 5 seconds if the instance gets a spot termination. If it does, it’ll write out an ABORT file that triggers StarCCM+ to shut down gracefully.
You’ll need to change the path of the /projects/ABORT file to the running directory of your StarCCM+ job.
- Create a post-install script
spot.shlike so:
#!/bin/bash
# write to a file
cat <<EOF >> /opt/spotinstancecheck
#!/bin/bash
while true
do
if [ -z $(curl -Is http://169.254.169.254/latest/meta-data/spot/termination-time | head -1 | grep 404 | cut -d \ -f 2) ]
then
# Write ABORT file for Star-CCM+ termination
sudo touch /projects/ABORT
break
else
# Spot instance not yet marked for termination.
sleep 5
fi
done
EOF
chmod +x /opt/spotinstancecheck
# Start Spot Instance check service if not already running
if ps ax | grep -v grep | grep "spotinst" > /dev/null
then
echo "Spot instance check service is already running." > /dev/null
else
# Start service
/opt/spotinstancecheck &
fi
A few things to note here:
/projects/should be the projects directory of your StarCCM+ job- This script is meant to run on the compute nodes, not on the HeadNode
- Upload to S3:
aws s3 cp spot.sh s3://your-bucket
- Update your ParallelCluster config to include the script in the
SlurmQueuesection:
In ParallelCluster Manager that looks like:
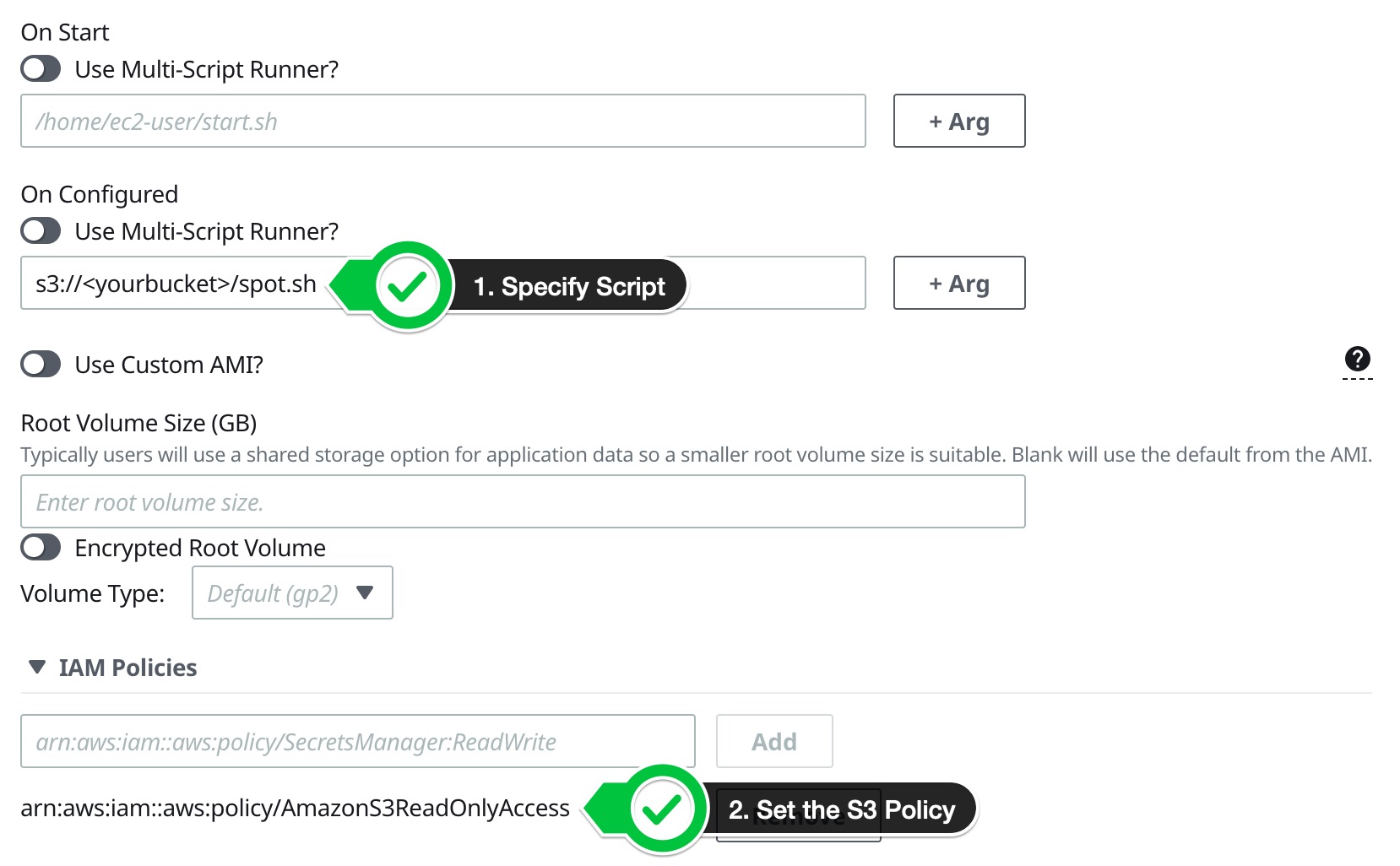
And in the config that looks like:
HeadNode:
InstanceType: t2.micro
Ssh:
KeyName: keypair
Networking:
SubnetId: subnet-1234567
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore
Dcv:
Enabled: true
Scheduling:
Scheduler: slurm
SlurmQueues:
- Name: queue0
ComputeResources:
- Name: queue0-c6i32xlarge
MinCount: 0
MaxCount: 64
InstanceType: c6i.32xlarge
Efa:
Enabled: true
Networking:
SubnetIds:
- subnet-1234567
PlacementGroup:
Enabled: true
CapacityType: SPOT
CustomActions:
OnNodeConfigured:
Script: s3://<yourbucket>/spot.sh
Iam:
AdditionalIamPolicies:
- Policy: arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess
Region: us-east-2
Image:
Os: alinux2
SharedStorage:
- Name: FsxLustre0
StorageType: FsxLustre
MountDir: /shared
FsxLustreSettings:
FileSystemId: fs-1234567890
- Create the cluster and in the next section we’ll test to make sure this is working.
Test
To test this we’re going to allocate a compute node, SSH in and make sure it’s running the script.
- Run
salloc -N 1and wait ~2 mins for a compute node to start running:
$ sinfo
PARTITION AVAIL TIMELIMIT NODES STATE NODELIST
compute* up infinite 64 idle~ compute-dy-c6i-[1-64]
$ salloc -N 1
salloc: Granted job allocation 6
- Once the instance comes up (you can check it’s state with
squeue) we can SSH in:
$ ssh compute-dy-c6i-1
- Check to make sure the script is running:
$ ps ax | grep -v grep | grep "spotinst"
2137 pts/0 S 0:00 /bin/bash /opt/spotinstancecheck
That’s it! now when your instance gets a Spot termination it’ll write out an ABORT file to /projects/ABORT and StarCCM+ will save state gracefully.