HPC7g instances in AWS ParallelCluster 👽
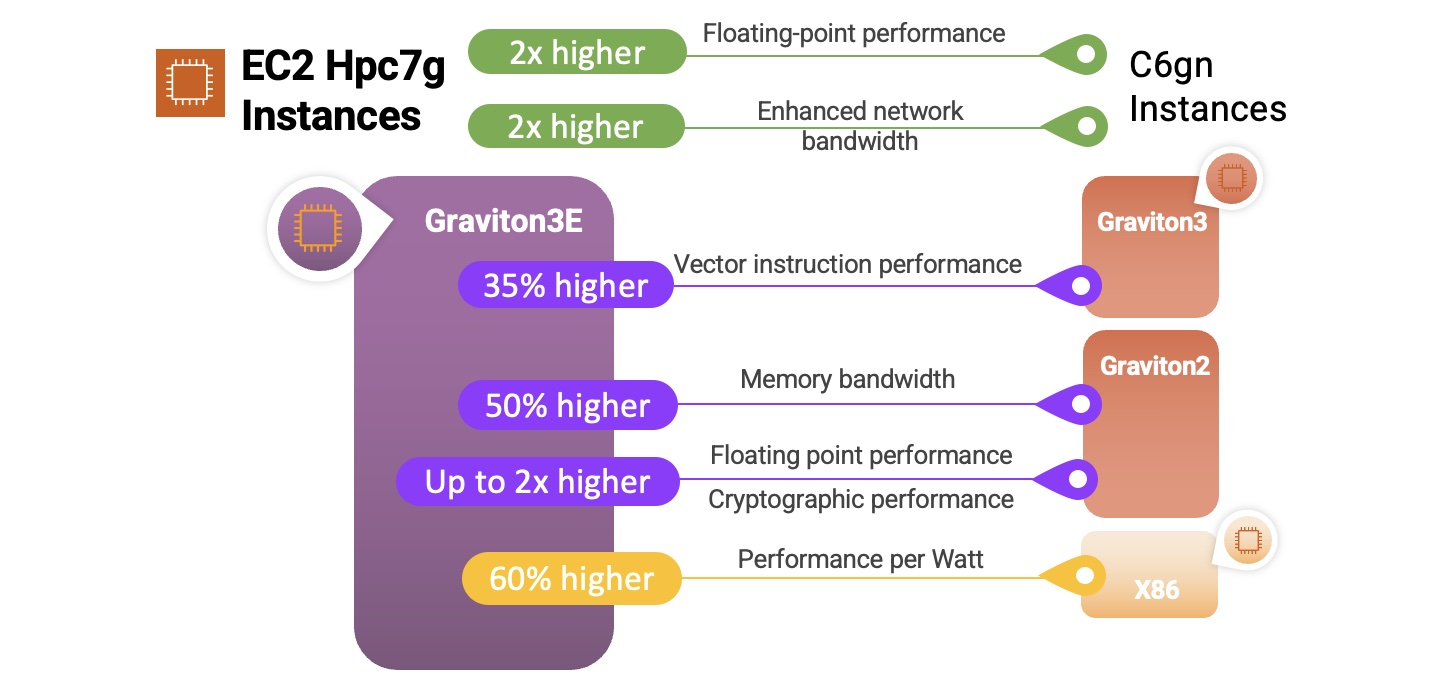
HPC7g instances are the first ARM based HPC instances in AWS. These instances combine excellent per-core pricing, deep capacity pools and 200 GB EFA networking in order to create the perfect HPC instance for large-scale cost-effective simulations. There’s three different sizes:
| Instance Size | Cores | Memory (GiB) | EFA Network Bandwidth | Price (On-Demand in us-east-1) |
|---|---|---|---|---|
| hpc7g.4xlarge | 16 | 128 | 200 GBps | 1.683 |
| hpc7g.8xlarge | 32 | 128 | 200 GBps | 1.683 |
| hpc7g.16xlarge | 64 | 128 | 200 GBps | 1.683 |
The first thing you’ll notice is the t-shirt sizes (i.e. 4xlarge or 8xlarge) don’t differ in terms of memory or price, they only differ by the number of cores. Think of this as similar to restricting cores in order to get better memory bandwidth or higher total memory per-core.
In the next section we’ll show how to setup these instances with AWS ParallelCluster.
Setup
To deploy hpc7g instances we’ll need to create a ARM-specific cluster due to a restriction in AWS ParallelCluster that each cluster needs to share the same architecture i.e. arm64 or x86_64. See Multi-Cluster Mode for an example of how to link the two clusters.
The next important caveat is that the HPC7g instances can only be deployed in a private subnet in a single-AZ, at launch that’s only N. Virginia (us-east-1), use1-az6 Availability Zone.
-
Create a VPC and Subnet in N. Virginia. For simplicity I’ve provided a template that creates a private subnet in each Availability Zone. You’ll need to use the private subnet created in
use1-az6to get capacity. -
Download the following example template: hpc7g.yaml. You’ll need to substitute your SSH keyname, the subnet id’s for both a public subnet (to connect) and a private subnet (for compute nodes), and anything else specific to your account.
The template creates the following resources:
Field Value Description Head Node c7g.xlargeThis instance is responsible for running slurm scheduler and allowing users to login. This is the smallest possible size slurmctld can use (4 cores and 8 GB RAM), it also matches the same neoversev1 core-architecture that the hpc7g.16xlargeinstances has so if you compile code and it does micro-architecture detection it’ll have the proper flags set.Compute Node hpc7g.16xlargeThese are the compute nodes, make sure they’re in the subnet created in use1-az6.Filesystem FSx Lustre We recommend using FSx Lustre as the shared filesystem. Once the template is modified, you can create the cluster like so:
pcluster create-cluster -n arm64 -c hpc7g.yaml
Install Arm Performance Libraries
Once the cluster is CREATE_COMPLETE we can install Arm Performance Libraries and a version of gcc that supports neoversev1 cores using Spack.
-
First install Spack on the FSx Lustre filesystem following instructions here
-
we’ll first install ARM Compiler for Linux (acfl) which has support for the
Neoversev1core:spack install acfl spack load acfl spack compiler find spack unload acfl -
Next we’ll install ARM Performance Libraries (armpl) a set of performance libraries including
BLAS,LAPACK,FFT, ect.spack install armpl-gcc -
You’ll now see a
armcompiler when you list out compilers:spack compilers
Restricting Cores
If we look back at the t-shirt sizes we’ll see that they’re already restricted in terms of cores.
| Instance Size | Cores | Memory (GiB) | EFA Network Bandwidth | Price (On-Demand in us-east-1) |
|---|---|---|---|---|
| hpc7g.4xlarge | 16 | 128 | 200 GBps | 1.683 |
| hpc7g.8xlarge | 32 | 128 | 200 GBps | 1.683 |
| hpc7g.16xlarge | 64 | 128 | 200 GBps | 1.683 |
To submit jobs that use a specific instance type, specify the constraint flag and the instance name:
salloc --constraint "hpc7g.4xlarge"
# wait for the instance to come up
Once the instance is running, you can ssh in and see that it does indeed have fewer cores but equivalent memory.
ssh hpc7g-dy-hpc7g-4xlarge-1
$ lscpu
Architecture: aarch64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Thread(s) per core: 1
Core(s) per socket: 16
Socket(s): 1
NUMA node(s): 1
Vendor ID: ARM
Model: 1
Stepping: r1p1
BogoMIPS: 2100.00
L1d cache: 64K
L1i cache: 64K
L2 cache: 1024K
L3 cache: 32768K
NUMA node0 CPU(s): 0-15
Flags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm jscvt fcma lrcpc dcpop sha3sm3 sm4 asimddp sha512 sve asimdfhm dit uscat ilrcpc flagm ssbs paca pacg dcpodp svei8mm svebf16 i8mm bf16 dgh rng
Slurm Multi-Cluster Mode
Slurm supports a feature called multi-cluster mode this allows you to submit jobs across multiple clusters, making it possible to submit from the x86 cluster to the arm cluster. For example, I could submit a job and specify the aarch64 cluster with the hpc7g partition like so:
sbatch --cluster aarch64 ...
This setup of this is outside of the scope of this blogpost, but please see Configure Slurm Multi-Cluster Mode for instructions.