Slurm Failover from Spot to On-Demand
Spot pricing, up to 90% off On-Demand, is enticing but comes with the caveat that your jobs can get terminated with only a 2-minute warning. So what happens when your instance gets a Spot termination and you need to finish that job?
In the following blogpost I present a solution that’ll re-run failed Spot jobs on On-Demand. If you combine this with a benchmarking solution such as Gromacs Checkpointing or StarCCM+ Save State you can resume from the last checkpoint.
Setup
In AWS ParallelCluster you can setup a cluster with two queues, one for Spot pricing and one for On-demand. When a job fails, due to a spot reclamation, you can automatically re-queue that job to the On-Demand queue.
To set that up, first create a cluster with a Spot and OnDemand queue:
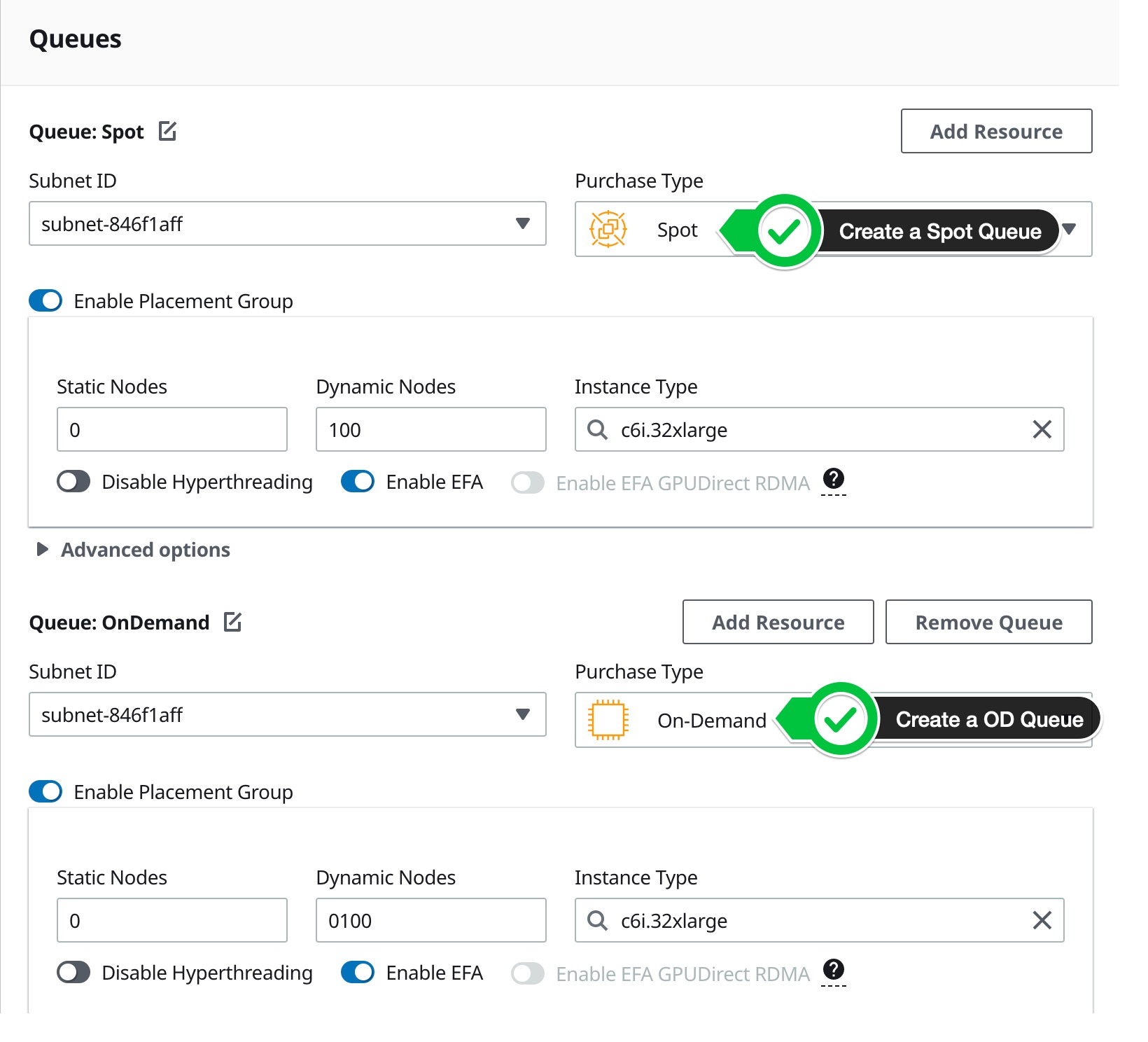
Confirm the yaml looks like the following:
- Name: od
ComputeResources:
- Name: c6i-od-c6i32xlarge
MinCount: 0
MaxCount: 4
InstanceType: c6i.32xlarge
Efa:
Enabled: true
GdrSupport: true
DisableSimultaneousMultithreading: true
Networking:
SubnetIds:
- subnet-846f1aff
PlacementGroup:
Enabled: true
- Name: spot
ComputeResources:
- Name: c6i-spot-c6i32xlarge
MaxCount: 4
InstanceType: c6i.32xlarge
Networking:
SubnetIds:
- subnet-846f1aff
CapacityType: SPOT
Next submit your job like so:
$ sbatch -p spot --norequeue submit.sbatch
Submitted job with id 1
$ sbatch -p od -d afternotok:1 submit.sbatch
Submitted job with id 2
--norequeuetells Slurm to not re-queue in the same queue as the first job.afternotok:1tells Slurm to only run the second job if the first one (job id 1) fails.