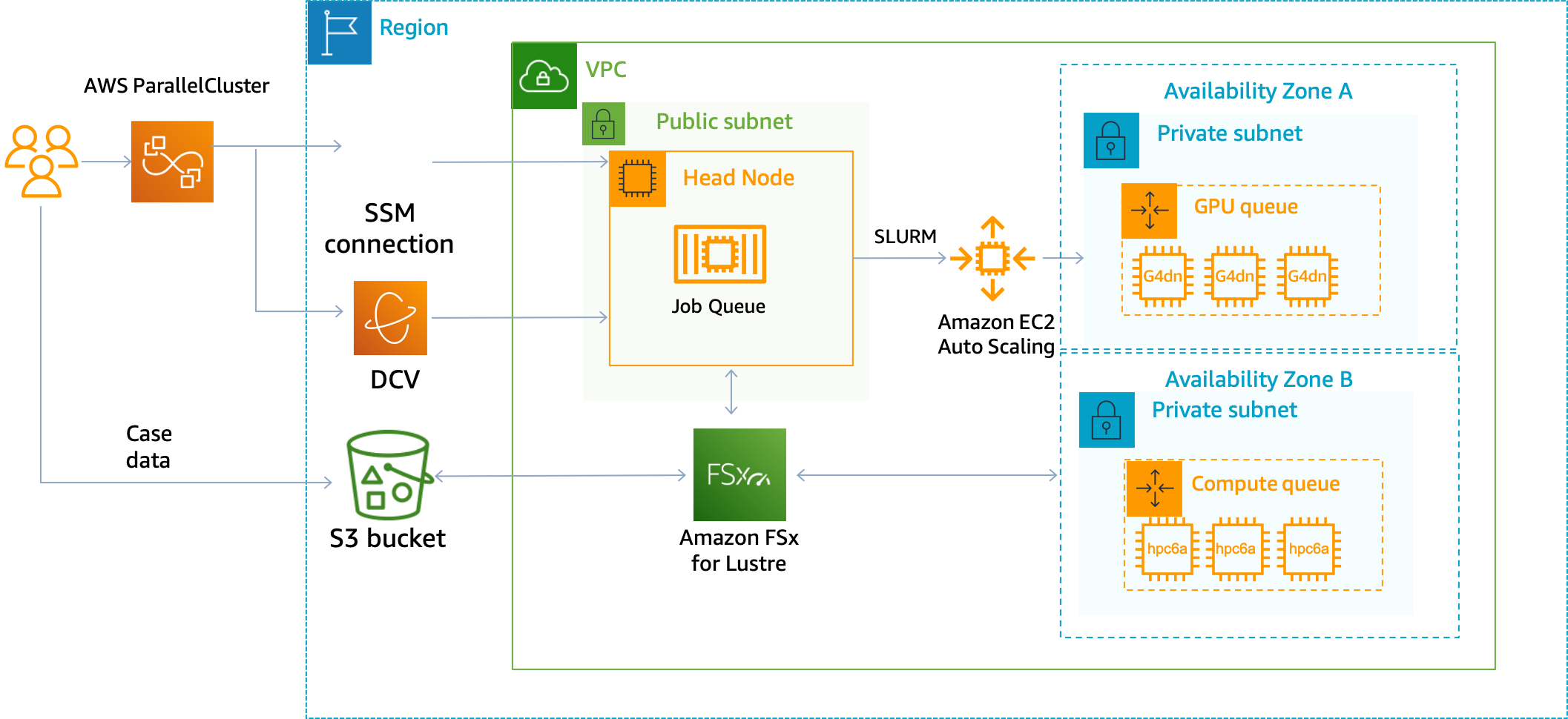
Multi-AZ AWS ParallelCluster 🌎
Today we launched a new version of AWS ParalleCluster, version 3.3.0. This version has a beta feature hidden in the release log:
- Allow for suppressing the
SingleSubnetValidatorfor Queues.
With this feature, we can setup a single AZ-per queue essentially allowing us to choose which Availibility Zone is associated with each queue. This is useful for capacity constrained instances, such as GPU and HPC instances which may exist in different availibility zones.
Note: This is a beta feature and as such will incur additional costs, such as cross-AZ traffic. For example, the home directory
/homeand the/opt/slurmdirectory are served from the HeadNode, so any traffic from the HeadNode to the compute that’s in another AZ will incur a charge of $.01/GB in each direction, which I explore below. Use at your own risk.
This is a beta launch and has some caveats:
- Clusters that create an FSx Lustre filesystem will throw an error about Multi-Subnets. The solution here is to create a filesystem then create the cluster and attach it.
- Traffic between different Availibility Zones will incur a charge of $.01/GB in each direction, which I explore below.
- Directories exported from the HeadNode, which include
/home,/opt/slurm,/opt/parallelcluster/shared, and/opt/intelare hosted in the same AZ as the HeadNode.
Setup
-
Install AWS ParallelCluster 3.3.0 on the CLI (this isn’t availaible yet in pcluster manager 😢)
pip3 install aws-parallelcluster==3.3.0 -
Setup a cluster config with a unique subnet per-queue. Here’s an example configuration you can start with. It has the
hpc6a.48xlargewhich os only supported inus-east-1band thec6i.32xlargewhich is supported in all AZ’s but can be capacity constrained at certain times.HeadNode: InstanceType: c5.xlarge Ssh: KeyName: keypair Networking: SubnetId: subnet-123456789 LocalStorage: RootVolume: VolumeType: gp3 Iam: AdditionalIamPolicies: - Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore Dcv: Enabled: true Scheduling: Scheduler: slurm SlurmQueues: - Name: us-east-2b ComputeResources: - Name: queue0-hpc6a48xlarge MinCount: 0 MaxCount: 64 InstanceType: hpc6a.48xlarge Efa: Enabled: true GdrSupport: true Networking: SubnetIds: - subnet-846f1aff PlacementGroup: Enabled: true ComputeSettings: LocalStorage: RootVolume: VolumeType: gp3 - Name: us-east-2c ComputeResources: - Name: queue1-c6i32xlarge MinCount: 0 MaxCount: 6 InstanceType: c6i.32xlarge Efa: Enabled: true GdrSupport: true DisableSimultaneousMultithreading: true ComputeSettings: LocalStorage: RootVolume: VolumeType: gp3 Networking: SubnetIds: - subnet-8b15a7c6 PlacementGroup: Enabled: true SlurmSettings: QueueUpdateStrategy: DRAIN EnableMemoryBasedScheduling: true Region: us-east-2 Image: Os: alinux2 -
Create the cluster (has be on the CLI) with the flag
--suppress-validators type:SingleSubnetValidator, i.e.pcluster create-cluster -n multi-az -c config-multi-az.yaml --suppress-validators type:SingleSubnetValidator
Performance 🏎
To test performance I installed ior, a tool to test filesystem performance.
us-east-2b
This is the control case, FSx Lustre is co-located in us-east-2b.
Max Write: 694.41 MiB/sec
Max Read: 38430.23 MiB/sec
us-east-2c
Max Write: 708.09 MiB/sec
Max Read: 49131.06 MiB/sec
us-east-2a
Max Write: 670.88 MiB/sec
Max Read: 37749.35 MiB/sec
As you can see, there’s a negible difference in performance. In other words performance is norminal 👌.
Cost 💰
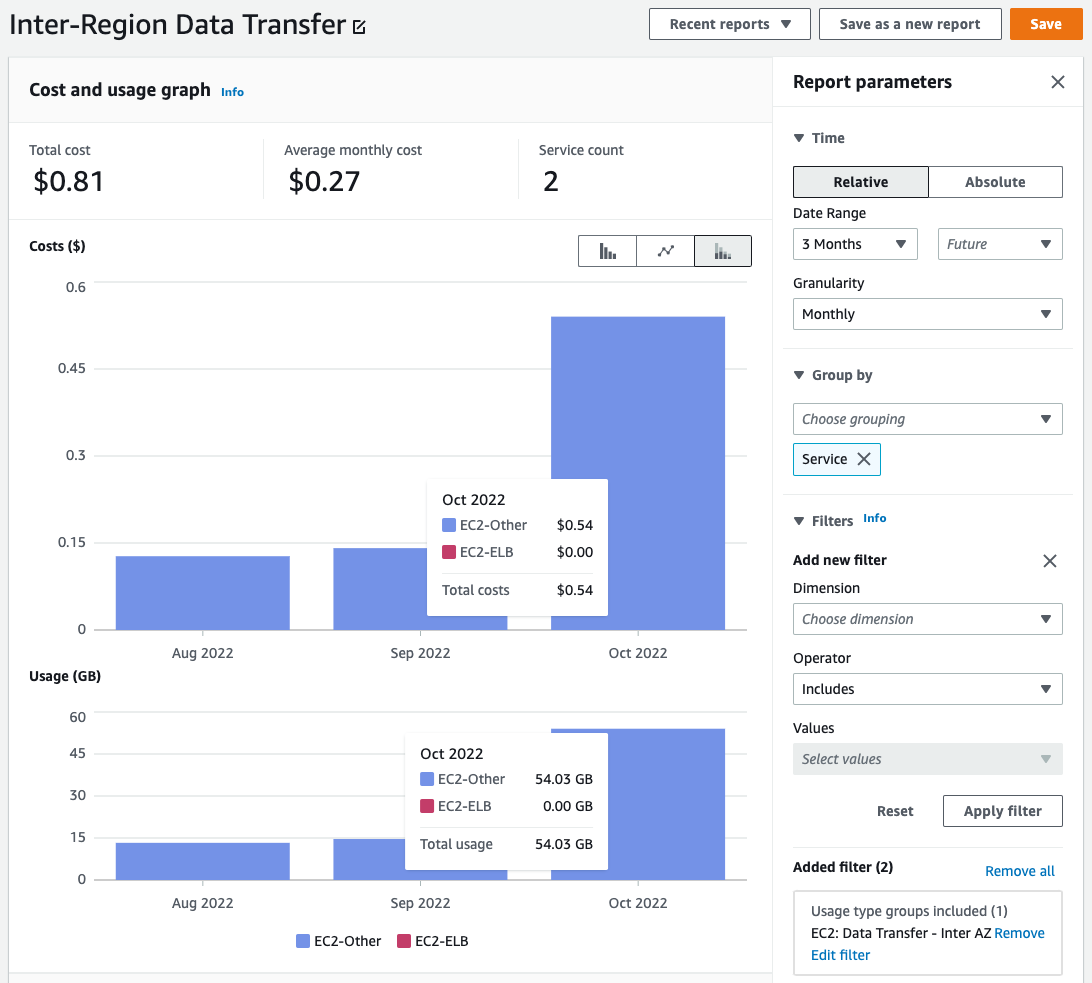
Traffic between different Availibility Zones incurs a small charge of $.01/GB as documented here. That seems minimal but how do we measure it on a real cluster?
To measure this, I went to the cost explorer console and filtered by the inter-AZ charges for that specific cluster.
- Go to the Cost Explorer Console
- Group by Service
- Add a secondary filter EC2: Data Transfer - Inter AZ
- You can then filter down by a specific cluster, select Tag then parallelcluster:cluster_name then select the cluster you’re interested in. See Cost Explorer with AWS ParallelCluster.