Local Storage for HPC Jobs with EBS 🗂
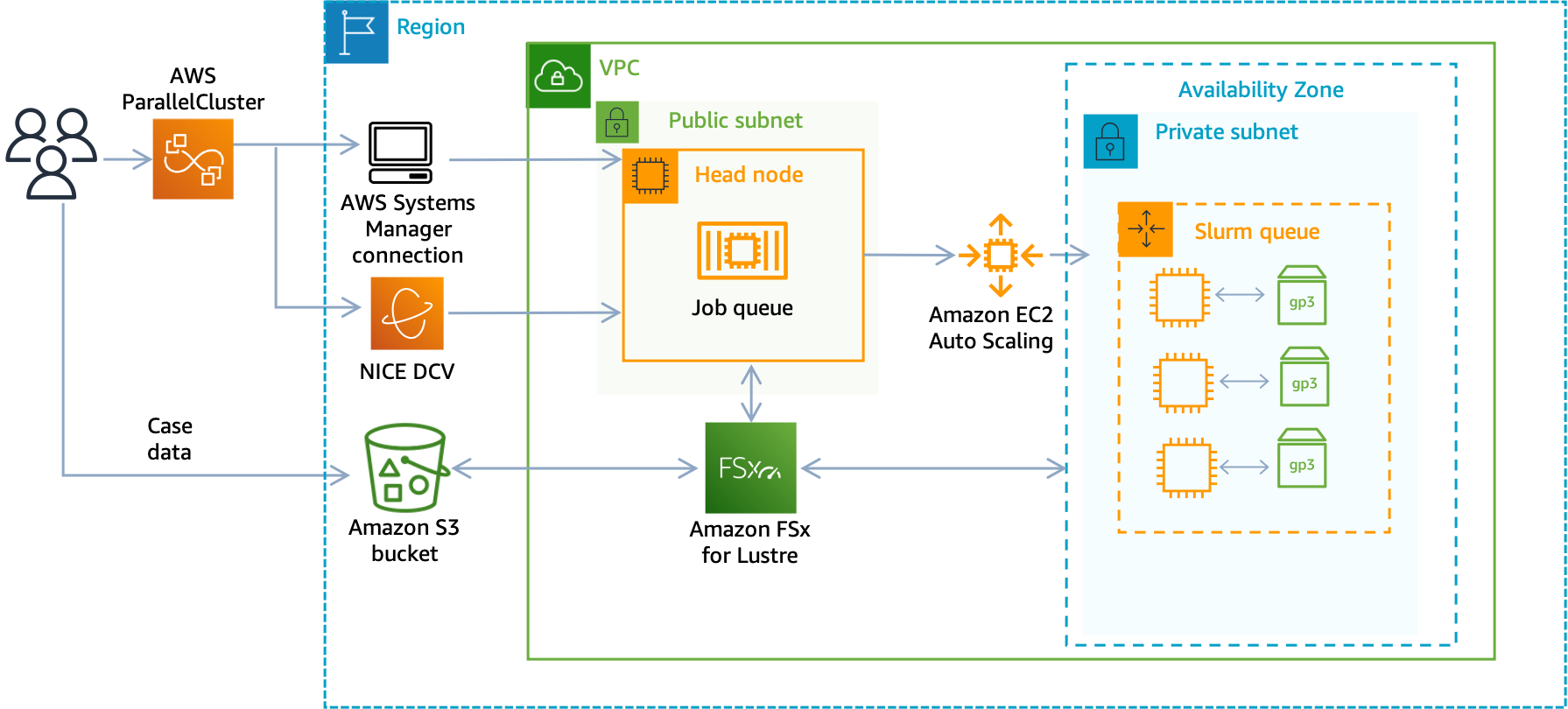
In previous blogposts we looked at several approaches to add shared storage to a cluster, these all focus on mounting a shared filesystem. If you have Multi-Node (MPI) style jobs, this is likely a requirement. You can follow those guides below:
- Mount FSx Netapp ONTAP with AWS ParallelCluster
- Setup FSx Lustre PERSISTENT_2 with AWS ParallelCluster
- Mount Additional EFS/FSx Lustre Filesystems in AWS ParallelCluster
Let’s say you don’t need shared storage but rather local storage on each compute node. There’s several ways to do this, by far the easiest is to just use an instance with local storage, instances such as the c6id.32xlarge, or any instance with a d in the name, have local NVME backed storage. This is automatically mounted at /scratch on the compute nodes.
Let’s say you want to use a an instance type that doesn’t have NVME but you want fast local storage mounted on that instance. Your next best option to mount an additional EBS drive to the instance.
Setup
-
Create a script called
attach_ebs.shwith the following content:#!/bin/sh # copyright Sean Smith <seaam@amazon.com> # attach_ebs.sh - Attach an EBS volume to an EC2 instance. # Usage: # attach_ebs.sh /scratch gp2|gp3|io1|io2 100 /dev/xvdb # # 1. Create a EBS volume # 2. wait for volume to create # 3. attach volume # 4. wait for volume to attach # 5. format filesystem # 6. mount filesystem # 7. persist volume after reboots # 8. Set DeleteOnTerminate to cleanup volume mount_point="${1:-/scratch}" type="${2:-gp3}" size="${3:-100}" device=${4:-/dev/sdf} az=$(curl -s http://169.254.169.254/latest/meta-data/placement/availability-zone) region=$(curl -s http://169.254.169.254/latest/dynamic/instance-identity/document | jq -r .region) instance_id=$(curl -s http://169.254.169.254/latest/meta-data/instance-id) # 1. create ebs volume volume_id=$(aws ec2 --region $region create-volume \ --availability-zone ${az} \ --volume-type ${type} \ --size ${size} | jq -r .VolumeId) echo "Created $volume_id..." # 2. wait for volume to create aws ec2 --region $region wait volume-available \ --volume-ids ${volume_id} # 3. attach volume aws ec2 --region $region attach-volume \ --device ${device} \ --instance-id ${instance_id} \ --volume-id ${volume_id} # 4. wait until volume is attached DEVICE_STATE="unknown" until [ "${DEVICE_STATE}" == "attached" ]; do DEVICE_STATE=$(aws ec2 describe-volumes \ --region ${region} \ --filters \ Name=attachment.instance-id,Values=${instance_id} \ Name=attachment.device,Values=${device} \ --query Volumes[].Attachments[].State \ --output text) sleep 5 done # 5. format filesystem mkfs -t xfs ${device} # 6. mount filesystem mkdir -p ${mount_point} mount ${device} ${mount_point} # 7. Persist Volume after reboots by putting it into /etc/fstab echo "${device} ${mount_point} xfs defaults,nofail 0 2" >> /etc/fstab # 8. Set DeleteOnTerminate to cleanup volume aws ec2 modify-instance-attribute --instance-id ${instance_id} --block-device-mappings "[{\"DeviceName\": \"${device}\",\"Ebs\":{\"DeleteOnTermination\":true}}]" -
Upload it to an S3 bucket. For your convenience, I’ve also hosted the script at
https://swsmith.cc/scripts/attach_ebs.sh.aws s3 cp attach_ebs.sh s3://bucket/ -
Create a cluster with AWS ParallelCluster based on ebs.yaml and specify
attach_ebs.shas a post install script.- In addition you’ll need the IAM policies
arn:aws:iam::aws:policy/AmazonEC2FullAccessandarn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess
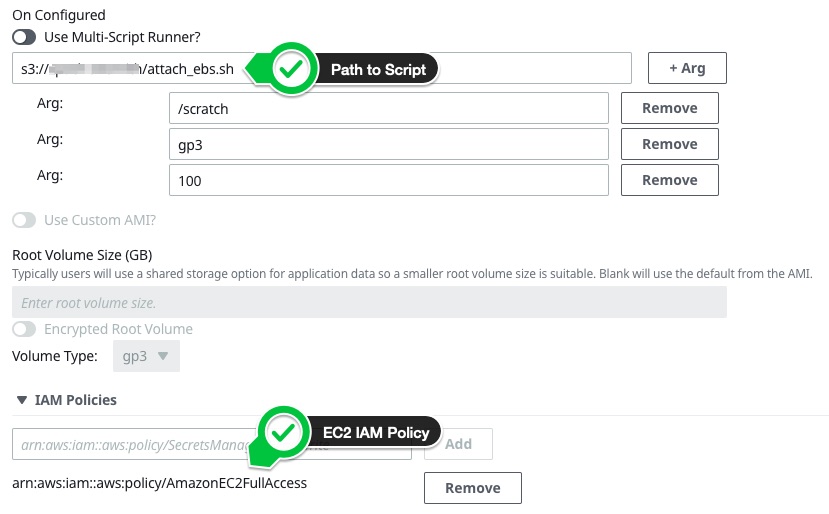
The config will look something like:
HeadNode: InstanceType: t2.micro Ssh: KeyName: keypair Networking: SubnetId: subnet-1234567 LocalStorage: RootVolume: VolumeType: gp3 Iam: AdditionalIamPolicies: - Policy: arn:aws:iam::aws:policy/AmazonSSMManagedInstanceCore Scheduling: Scheduler: slurm SlurmQueues: - Name: queue0 ComputeResources: - Name: queue0-c52xlarge MinCount: 0 MaxCount: 4 InstanceType: c5.2xlarge Networking: SubnetIds: - subnet-1234567 ComputeSettings: LocalStorage: RootVolume: VolumeType: gp3 CustomActions: OnNodeConfigured: Script: s3://bucket/attach_ebs.sh Args: - /scratch - gp3 - '100' Iam: AdditionalIamPolicies: - Policy: arn:aws:iam::aws:policy/AmazonS3ReadOnlyAccess Region: us-east-2 Image: Os: alinux2 - In addition you’ll need the IAM policies
Test
After the cluster has finished creating, ssh in and spin up a compute node:
salloc -N 1
watch squeue
# wait a few minutes until job goes into 'R' running
ssh queue0-dy-queue0-c52xlarge-1
On the compute node you’ll see the /scratch directory mounted & with the correct storage size:
[ec2-user@ip-172-31-42-37 scratch]$ df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 473M 0 473M 0% /dev
tmpfs 483M 0 483M 0% /dev/shm
tmpfs 483M 568K 483M 1% /run
tmpfs 483M 0 483M 0% /sys/fs/cgroup
/dev/xvda1 35G 16G 20G 45% /
tmpfs 97M 0 97M 0% /run/user/0
/dev/xvdf 99G 24K 94G 1% /scratch
That’s it!
Debug
If the instance fails to create, you can debug it by looking at the /var/log/cloud-init-output.log file. Common errors include:
- IAM Permissions, make sure to attach the
EC2FullAccesspolicy. Note parallelcluster manager needs additional permissions to allow you to attach that policy. You can add them by following instructions here. This looks like:
An error occurred (UnauthorizedOperation) when calling the CreateVolume operation: You are not authorized to perform this operation. Encoded authorization failure message: zzdHSckogz8k6Y7...
- Specify the wrong device name, such as when using older i.e. t2 or c4 instances. These instances have an older block device mapping, and
/dev/sdfwill not work. You can read more about it here - Specify a duplicate device name. If you attempt to attach a secondary Amazon EBS volume to
/dev/sdf, the secondary EBS volume can’t successfully attach to the instance. This can cause the EBS volume to be stuck in the attaching state. See EBS Stuck attaching
To debug faster, I suggest runnning on the HeadNode like so:
# download from s3
wget https://swsmith.cc/scripts/attach_ebs.sh
# run as root
sudo bash attach_ebs.sh